Testing With Intent: TDD's Impact on Program Design
TDD’s three key impacts on program design are:
Stronger Boundaries
When practicing TDD, I tend to use more interfaces, and design them sooner.
Testing a set of “communicating components” is easier than one monolithic blob.
In Go, Reader is a common interface for a stream of bytes:
// Interface. Defines common behaviour.
type Reader interface {
Read(p []byte) (n int, err error)
}
// First implementation
buffer := bytes.NewBuffer()
// A different implementation
type CharRepeater struct {
char byte
}
func (c *CharRepeater) Read(p []byte) (n int, err error) {
for i := 0; i < len(p); i++ {
p[i] = c.char
}
return len(p), nil
}
bytes.Buffer is one implementation of Reader, and CharRepeater is another.
The Reader interface is a common abstraction. Both implementations are streams
of bytes we can read from. Which means we can interchange them. One
implementation for real life, and one for testing. The interfaces in your system
become natural test-hooks.
In Go, the implementor doesn’t have to declare what it implements. In Java you’d
have to say, “CharRepeater implements io.Reader”. So we can define interfaces
for other people’s code. This is one of my favourite things about Go.
Pure Functions
You can do testing, and even TDD, without pure functions. But, writing good
tests (and good code) will be much harder! What do I mean by “pure functions”?
Functions without side-effects. Ok, so what is a side-effect? Anything other
than the input or output of a function.
In a strict mathematical sense, a pure function is very simple:
\[f(x) = y\]
or, as a type signature:
\[f : Input \rightarrow Output\]
f takes some input, and returns some output. End of story.
An impure function has a lot more complexity:
\[f(x, (and\ other\ state)) = y\ (and\ other\ things\ happen) \\\]
or, as a type signature:
\[\begin{align*}
Secret\ &State \\
&\downarrow \\
f : Input &\rightarrow Output \\
&\downarrow \\
Side\ &Effects
\end{align*}\]
Along with input and output, the impure f also has secret state and side
effects to understand. It does some logging. Or, it uses some global variable.
Or, f horrifies us by changing some external state every time it runs.
One common source of secret input-state, and side-effects, is generating random
values. In Javascript that looks like:
// Secret State!
function impureFunc(value) {
Math.random() * value;
}
Changing randomness to a completely pure function is a bigger task. Because
Math.random() modifies it’s own internal state. For testing, changing the
source of randomness to a passed-in argument is good enough. By passing in
randSource we can take control of the random values used in the test:
// Only depends on the inputs
function pureFunc(randSource, value) {
randSource.random() * value;
}
Another common, and confusing, source of side-effects are functions which change
their inputs. Or even, functions which return their value in a piece of global
state, like:
// Modifies random things in the program!
var impureOutput = [];
function impureMakeRange() {
for(var i = 0; i < 5; i++){
impureOutput.push(impureFunc(5));
}
}
What if impureOutput already has data in it? Every time we call this function
we’ll get a different value. To test this, we’ll have to clean up the global
state (the impureOutput array) before and after every test. Hope we don’t miss
any! Otherwise our tests will leak all over each other. “Spooky action at a
distance” dependencies will creep between our test cases. A better way is to
model changes to global state as “transform” steps:
// Only modifies the output
function pureMakeRange() {
var pureOutput = [];
for(var i = 0; i < 5; i++){
pureOutput.push(pureFunc(5));
}
return pureOutput;
}
Better to be explicit about returning new values instead of modifying input
values. And, better to not rely on secret state inputs. Side-effects force you
to think about implementation details, and use doubles to test them.
External Dependency Wrappers
Of course, we can’t build our entire system from pure functions. At some point
we need to interact with the outside world. Querying databases, serving
websites, and printing to console. The key isn’t eliminating side-effects. It is
about managing side-effects.
We constrain side-effects by wrapping our external dependencies. More than that,
we concentrate them all in one place. This makes external dependencies easy to
test, and easy to mock.
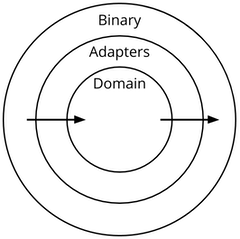
Because pure functions are easier to test, we use them for our domain logic. Our
programs look like this. Pure functions (or objects) in the middle, with
wrappers for external apis around that. This has strong, defined boundaries, and
is easy to test.
Don’t mock what you don’t own. We “own” external dependencies by giving
ourselves a nicer interface.
All-together, this looks like ports-and-adapters, or hexagonal architecture.
Go Wrapper Example
Suppose we had a domain function which uses Sendgrid to handle new user signups.
In Go, this looks like:
// What the library provides
import "github.com/sendgrid/sendgrid-go"
func NewSendClient(apiKey string) *Client {}
func (cl *Client) Send(email *mail.SGMailV3) (*rest.Response, error) {}
// The function we want to test:
func NewUserSignup(sg *sendgrid.Client, address, username string) {}
// Our test:
func TestNewUserSignupSendsEmail(t *testing.T) {
sg := sendgrid.NewSendClient(
"What key do we use for testing?",
)
sg.SandboxMode = true // Don't forget this!
NewUserSignup(sg, "[email protected]", "testuser1")
// How do we verify it sent??
}
Static types in the Sendgrid library include a lot of things we don’t care
about. Google tracking, Spam filtering, etc. This will make testing tedious and
painful. Instead, let’s wrap the library with an interface:
// Let's wrap the library:
type EmailSender interface {
Send(email *mail.SGMailV3)
}
// The function we want to test:
func NewUserSignup(sg EmailSender, address, username string) {}
// Our test:
func TestNewUserSignupSendsEmail(t *testing.T) {
sender := NewMockEmailSender()
NewUserSignup(sender, "[email protected]", "testuser1")
assert.Length(sender.sent, 1)
}
Our tests are already much easier to set up. Because we’re still relying on
the SGMailV3 type, this is still a bit awkward. In the best case, we should go further
and completely extract that out of our interface.
TDD’s three key impacts on program design are:
Stronger Boundaries
When practicing TDD, I tend to use more interfaces, and design them sooner. Testing a set of “communicating components” is easier than one monolithic blob.
In Go, Reader is a common interface for a stream of bytes:
// Interface. Defines common behaviour.
type Reader interface {
Read(p []byte) (n int, err error)
}
// First implementation
buffer := bytes.NewBuffer()
// A different implementation
type CharRepeater struct {
char byte
}
func (c *CharRepeater) Read(p []byte) (n int, err error) {
for i := 0; i < len(p); i++ {
p[i] = c.char
}
return len(p), nil
}
bytes.Buffer is one implementation of Reader, and CharRepeater is another.
The Reader interface is a common abstraction. Both implementations are streams
of bytes we can read from. Which means we can interchange them. One
implementation for real life, and one for testing. The interfaces in your system
become natural test-hooks.
In Go, the implementor doesn’t have to declare what it implements. In Java you’d have to say, “CharRepeater implements io.Reader”. So we can define interfaces for other people’s code. This is one of my favourite things about Go.
Pure Functions
You can do testing, and even TDD, without pure functions. But, writing good tests (and good code) will be much harder! What do I mean by “pure functions”? Functions without side-effects. Ok, so what is a side-effect? Anything other than the input or output of a function.
In a strict mathematical sense, a pure function is very simple:
\[f(x) = y\]or, as a type signature:
\[f : Input \rightarrow Output\]f takes some input, and returns some output. End of story.
An impure function has a lot more complexity:
\[f(x, (and\ other\ state)) = y\ (and\ other\ things\ happen) \\\]or, as a type signature:
\[\begin{align*} Secret\ &State \\ &\downarrow \\ f : Input &\rightarrow Output \\ &\downarrow \\ Side\ &Effects \end{align*}\]Along with input and output, the impure f also has secret state and side
effects to understand. It does some logging. Or, it uses some global variable.
Or, f horrifies us by changing some external state every time it runs.
One common source of secret input-state, and side-effects, is generating random values. In Javascript that looks like:
// Secret State!
function impureFunc(value) {
Math.random() * value;
}
Changing randomness to a completely pure function is a bigger task. Because
Math.random() modifies it’s own internal state. For testing, changing the
source of randomness to a passed-in argument is good enough. By passing in
randSource we can take control of the random values used in the test:
// Only depends on the inputs
function pureFunc(randSource, value) {
randSource.random() * value;
}
Another common, and confusing, source of side-effects are functions which change their inputs. Or even, functions which return their value in a piece of global state, like:
// Modifies random things in the program!
var impureOutput = [];
function impureMakeRange() {
for(var i = 0; i < 5; i++){
impureOutput.push(impureFunc(5));
}
}
What if impureOutput already has data in it? Every time we call this function
we’ll get a different value. To test this, we’ll have to clean up the global
state (the impureOutput array) before and after every test. Hope we don’t miss
any! Otherwise our tests will leak all over each other. “Spooky action at a
distance” dependencies will creep between our test cases. A better way is to
model changes to global state as “transform” steps:
// Only modifies the output
function pureMakeRange() {
var pureOutput = [];
for(var i = 0; i < 5; i++){
pureOutput.push(pureFunc(5));
}
return pureOutput;
}
Better to be explicit about returning new values instead of modifying input values. And, better to not rely on secret state inputs. Side-effects force you to think about implementation details, and use doubles to test them.
External Dependency Wrappers
Of course, we can’t build our entire system from pure functions. At some point we need to interact with the outside world. Querying databases, serving websites, and printing to console. The key isn’t eliminating side-effects. It is about managing side-effects.
We constrain side-effects by wrapping our external dependencies. More than that, we concentrate them all in one place. This makes external dependencies easy to test, and easy to mock.
Because pure functions are easier to test, we use them for our domain logic. Our programs look like this. Pure functions (or objects) in the middle, with wrappers for external apis around that. This has strong, defined boundaries, and is easy to test.
Don’t mock what you don’t own. We “own” external dependencies by giving ourselves a nicer interface.
All-together, this looks like ports-and-adapters, or hexagonal architecture.
Go Wrapper Example
Suppose we had a domain function which uses Sendgrid to handle new user signups. In Go, this looks like:
// What the library provides
import "github.com/sendgrid/sendgrid-go"
func NewSendClient(apiKey string) *Client {}
func (cl *Client) Send(email *mail.SGMailV3) (*rest.Response, error) {}
// The function we want to test:
func NewUserSignup(sg *sendgrid.Client, address, username string) {}
// Our test:
func TestNewUserSignupSendsEmail(t *testing.T) {
sg := sendgrid.NewSendClient(
"What key do we use for testing?",
)
sg.SandboxMode = true // Don't forget this!
NewUserSignup(sg, "[email protected]", "testuser1")
// How do we verify it sent??
}
Static types in the Sendgrid library include a lot of things we don’t care about. Google tracking, Spam filtering, etc. This will make testing tedious and painful. Instead, let’s wrap the library with an interface:
// Let's wrap the library:
type EmailSender interface {
Send(email *mail.SGMailV3)
}
// The function we want to test:
func NewUserSignup(sg EmailSender, address, username string) {}
// Our test:
func TestNewUserSignupSendsEmail(t *testing.T) {
sender := NewMockEmailSender()
NewUserSignup(sender, "[email protected]", "testuser1")
assert.Length(sender.sent, 1)
}
Our tests are already much easier to set up. Because we’re still relying on
the SGMailV3 type, this is still a bit awkward. In the best case, we should go further
and completely extract that out of our interface.